503 lines
21 KiB
Markdown
503 lines
21 KiB
Markdown
---
|
||
layout: forward
|
||
target: https://github.com/google/mediapipe/blob/master/docs/solutions/holistic.md
|
||
title: Holistic
|
||
parent: MediaPipe Legacy Solutions
|
||
nav_order: 6
|
||
---
|
||
|
||
# MediaPipe Holistic
|
||
{: .no_toc }
|
||
|
||
<details close markdown="block">
|
||
<summary>
|
||
Table of contents
|
||
</summary>
|
||
{: .text-delta }
|
||
1. TOC
|
||
{:toc}
|
||
</details>
|
||
---
|
||
|
||
**Attention:** *Thank you for your interest in MediaPipe Solutions.
|
||
As of March 1, 2023, this solution is planned to be upgraded to a new MediaPipe
|
||
Solution. For more information, see the
|
||
[MediaPipe Solutions](https://developers.google.com/mediapipe/solutions/guide#legacy)
|
||
site.*
|
||
|
||
----
|
||
|
||
## Overview
|
||
|
||
Live perception of simultaneous [human pose](./pose.md),
|
||
[face landmarks](./face_mesh.md), and [hand tracking](./hands.md) in real-time
|
||
on mobile devices can enable various modern life applications: fitness and sport
|
||
analysis, gesture control and sign language recognition, augmented reality
|
||
try-on and effects. MediaPipe already offers fast and accurate, yet separate,
|
||
solutions for these tasks. Combining them all in real-time into a semantically
|
||
consistent end-to-end solution is a uniquely difficult problem requiring
|
||
simultaneous inference of multiple, dependent neural networks.
|
||
|
||
 |
|
||
:----------------------------------------------------------------------------------------------------: |
|
||
*Fig 1. Example of MediaPipe Holistic.* |
|
||
|
||
## ML Pipeline
|
||
|
||
The MediaPipe Holistic pipeline integrates separate models for
|
||
[pose](./pose.md), [face](./face_mesh.md) and [hand](./hands.md) components,
|
||
each of which are optimized for their particular domain. However, because of
|
||
their different specializations, the input to one component is not well-suited
|
||
for the others. The pose estimation model, for example, takes a lower, fixed
|
||
resolution video frame (256x256) as input. But if one were to crop the hand and
|
||
face regions from that image to pass to their respective models, the image
|
||
resolution would be too low for accurate articulation. Therefore, we designed
|
||
MediaPipe Holistic as a multi-stage pipeline, which treats the different regions
|
||
using a region appropriate image resolution.
|
||
|
||
First, we estimate the human pose (top of Fig 2) with [BlazePose](./pose.md)’s
|
||
pose detector and subsequent landmark model. Then, using the inferred pose
|
||
landmarks we derive three regions of interest (ROI) crops for each hand (2x) and
|
||
the face, and employ a re-crop model to improve the ROI. We then crop the
|
||
full-resolution input frame to these ROIs and apply task-specific face and hand
|
||
models to estimate their corresponding landmarks. Finally, we merge all
|
||
landmarks with those of the pose model to yield the full 540+ landmarks.
|
||
|
||
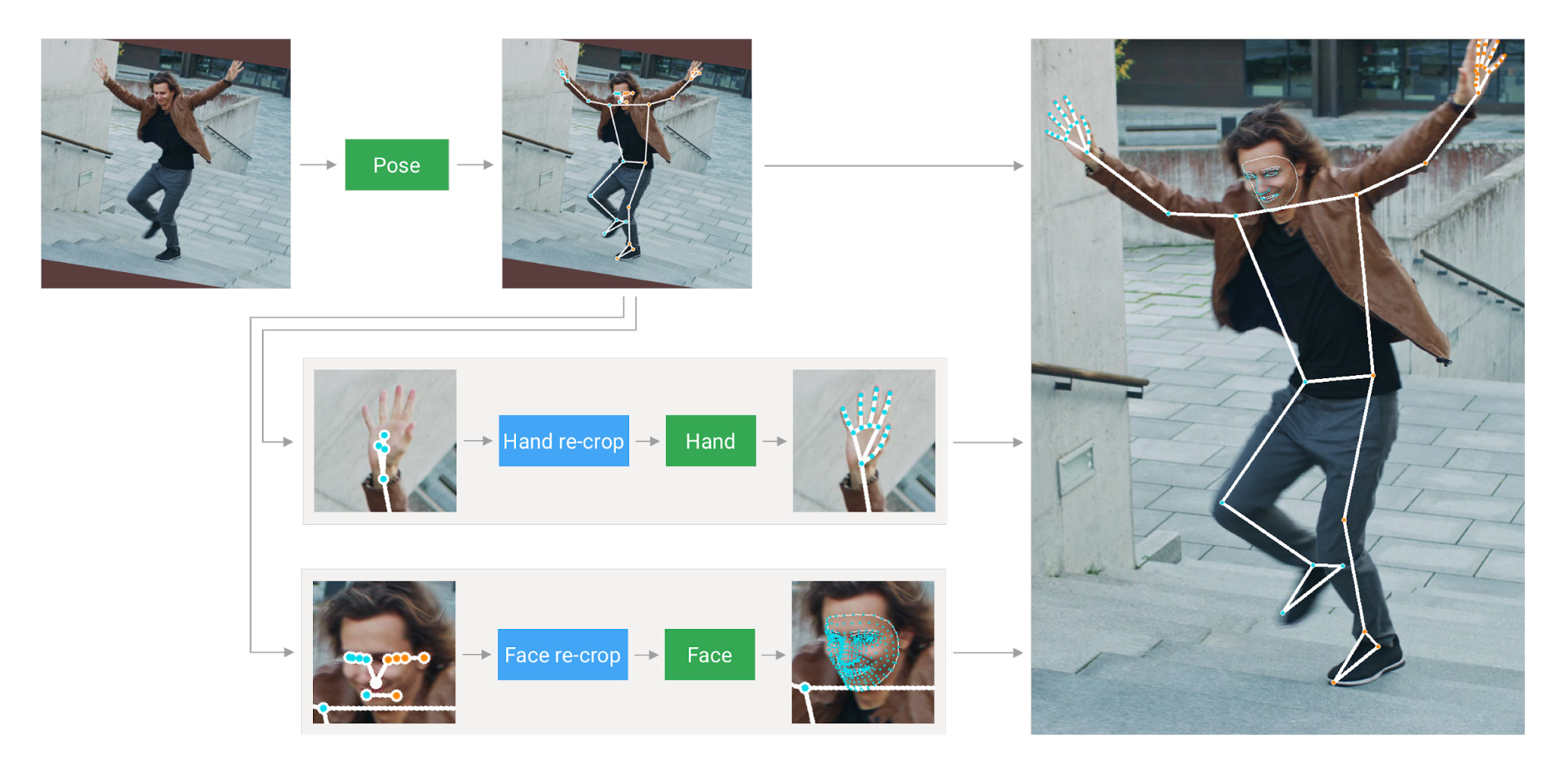 |
|
||
:------------------------------------------------------------------------------: |
|
||
*Fig 2. MediaPipe Holistic Pipeline Overview.* |
|
||
|
||
To streamline the identification of ROIs for face and hands, we utilize a
|
||
tracking approach similar to the one we use for standalone
|
||
[face](./face_mesh.md) and [hand](./hands.md) pipelines. It assumes that the
|
||
object doesn't move significantly between frames and uses estimation from the
|
||
previous frame as a guide to the object region on the current one. However,
|
||
during fast movements, the tracker can lose the target, which requires the
|
||
detector to re-localize it in the image. MediaPipe Holistic uses
|
||
[pose](./pose.md) prediction (on every frame) as an additional ROI prior to
|
||
reducing the response time of the pipeline when reacting to fast movements. This
|
||
also enables the model to retain semantic consistency across the body and its
|
||
parts by preventing a mixup between left and right hands or body parts of one
|
||
person in the frame with another.
|
||
|
||
In addition, the resolution of the input frame to the pose model is low enough
|
||
that the resulting ROIs for face and hands are still too inaccurate to guide the
|
||
re-cropping of those regions, which require a precise input crop to remain
|
||
lightweight. To close this accuracy gap we use lightweight face and hand re-crop
|
||
models that play the role of
|
||
[spatial transformers](https://arxiv.org/abs/1506.02025) and cost only ~10% of
|
||
corresponding model's inference time.
|
||
|
||
The pipeline is implemented as a MediaPipe
|
||
[graph](https://github.com/google/mediapipe/tree/master/mediapipe/graphs/holistic_tracking/holistic_tracking_gpu.pbtxt)
|
||
that uses a
|
||
[holistic landmark subgraph](https://github.com/google/mediapipe/tree/master/mediapipe/modules/holistic_landmark/holistic_landmark_gpu.pbtxt)
|
||
from the
|
||
[holistic landmark module](https://github.com/google/mediapipe/tree/master/mediapipe/modules/holistic_landmark)
|
||
and renders using a dedicated
|
||
[holistic renderer subgraph](https://github.com/google/mediapipe/tree/master/mediapipe/graphs/holistic_tracking/holistic_tracking_to_render_data.pbtxt).
|
||
The
|
||
[holistic landmark subgraph](https://github.com/google/mediapipe/tree/master/mediapipe/modules/holistic_landmark/holistic_landmark_gpu.pbtxt)
|
||
internally uses a
|
||
[pose landmark module](https://github.com/google/mediapipe/tree/master/mediapipe/modules/pose_landmark)
|
||
,
|
||
[hand landmark module](https://github.com/google/mediapipe/tree/master/mediapipe/modules/hand_landmark)
|
||
and
|
||
[face landmark module](https://github.com/google/mediapipe/tree/master/mediapipe/modules/face_landmark/).
|
||
Please check them for implementation details.
|
||
|
||
Note: To visualize a graph, copy the graph and paste it into
|
||
[MediaPipe Visualizer](https://viz.mediapipe.dev/). For more information on how
|
||
to visualize its associated subgraphs, please see
|
||
[visualizer documentation](../tools/visualizer.md).
|
||
|
||
## Models
|
||
|
||
### Landmark Models
|
||
|
||
MediaPipe Holistic utilizes the pose, face and hand landmark models in
|
||
[MediaPipe Pose](./pose.md), [MediaPipe Face Mesh](./face_mesh.md) and
|
||
[MediaPipe Hands](./hands.md) respectively to generate a total of 543 landmarks
|
||
(33 pose landmarks, 468 face landmarks, and 21 hand landmarks per hand).
|
||
|
||
### Hand Recrop Model
|
||
|
||
For cases when the accuracy of the pose model is low enough that the resulting
|
||
ROIs for hands are still too inaccurate we run the additional lightweight hand
|
||
re-crop model that play the role of
|
||
[spatial transformer](https://arxiv.org/abs/1506.02025) and cost only ~10% of
|
||
hand model inference time.
|
||
|
||
## Solution APIs
|
||
|
||
### Cross-platform Configuration Options
|
||
|
||
Naming style and availability may differ slightly across platforms/languages.
|
||
|
||
#### static_image_mode
|
||
|
||
If set to `false`, the solution treats the input images as a video stream. It
|
||
will try to detect the most prominent person in the very first images, and upon
|
||
a successful detection further localizes the pose and other landmarks. In
|
||
subsequent images, it then simply tracks those landmarks without invoking
|
||
another detection until it loses track, on reducing computation and latency. If
|
||
set to `true`, person detection runs every input image, ideal for processing a
|
||
batch of static, possibly unrelated, images. Default to `false`.
|
||
|
||
#### model_complexity
|
||
|
||
Complexity of the pose landmark model: `0`, `1` or `2`. Landmark accuracy as
|
||
well as inference latency generally go up with the model complexity. Default to
|
||
`1`.
|
||
|
||
#### smooth_landmarks
|
||
|
||
If set to `true`, the solution filters pose landmarks across different input
|
||
images to reduce jitter, but ignored if [static_image_mode](#static_image_mode)
|
||
is also set to `true`. Default to `true`.
|
||
|
||
#### enable_segmentation
|
||
|
||
If set to `true`, in addition to the pose, face and hand landmarks the solution
|
||
also generates the segmentation mask. Default to `false`.
|
||
|
||
#### smooth_segmentation
|
||
|
||
If set to `true`, the solution filters segmentation masks across different input
|
||
images to reduce jitter. Ignored if [enable_segmentation](#enable_segmentation)
|
||
is `false` or [static_image_mode](#static_image_mode) is `true`. Default to
|
||
`true`.
|
||
|
||
#### refine_face_landmarks
|
||
|
||
Whether to further refine the landmark coordinates around the eyes and lips, and
|
||
output additional landmarks around the irises. Default to `false`.
|
||
|
||
#### min_detection_confidence
|
||
|
||
Minimum confidence value (`[0.0, 1.0]`) from the person-detection model for the
|
||
detection to be considered successful. Default to `0.5`.
|
||
|
||
#### min_tracking_confidence
|
||
|
||
Minimum confidence value (`[0.0, 1.0]`) from the landmark-tracking model for the
|
||
pose landmarks to be considered tracked successfully, or otherwise person
|
||
detection will be invoked automatically on the next input image. Setting it to a
|
||
higher value can increase robustness of the solution, at the expense of a higher
|
||
latency. Ignored if [static_image_mode](#static_image_mode) is `true`, where
|
||
person detection simply runs on every image. Default to `0.5`.
|
||
|
||
### Output
|
||
|
||
Naming style may differ slightly across platforms/languages.
|
||
|
||
#### pose_landmarks
|
||
|
||
A list of pose landmarks. Each landmark consists of the following:
|
||
|
||
* `x` and `y`: Landmark coordinates normalized to `[0.0, 1.0]` by the image
|
||
width and height respectively.
|
||
* `z`: Should be discarded as currently the model is not fully trained to
|
||
predict depth, but this is something on the roadmap.
|
||
* `visibility`: A value in `[0.0, 1.0]` indicating the likelihood of the
|
||
landmark being visible (present and not occluded) in the image.
|
||
|
||
#### pose_world_landmarks
|
||
|
||
Another list of pose landmarks in world coordinates. Each landmark consists of
|
||
the following:
|
||
|
||
* `x`, `y` and `z`: Real-world 3D coordinates in meters with the origin at the
|
||
center between hips.
|
||
* `visibility`: Identical to that defined in the corresponding
|
||
[pose_landmarks](#pose_landmarks).
|
||
|
||
#### face_landmarks
|
||
|
||
A list of 468 face landmarks. Each landmark consists of `x`, `y` and `z`. `x`
|
||
and `y` are normalized to `[0.0, 1.0]` by the image width and height
|
||
respectively. `z` represents the landmark depth with the depth at center of the
|
||
head being the origin, and the smaller the value the closer the landmark is to
|
||
the camera. The magnitude of `z` uses roughly the same scale as `x`.
|
||
|
||
#### left_hand_landmarks
|
||
|
||
A list of 21 hand landmarks on the left hand. Each landmark consists of `x`, `y`
|
||
and `z`. `x` and `y` are normalized to `[0.0, 1.0]` by the image width and
|
||
height respectively. `z` represents the landmark depth with the depth at the
|
||
wrist being the origin, and the smaller the value the closer the landmark is to
|
||
the camera. The magnitude of `z` uses roughly the same scale as `x`.
|
||
|
||
#### right_hand_landmarks
|
||
|
||
A list of 21 hand landmarks on the right hand, in the same representation as
|
||
[left_hand_landmarks](#left_hand_landmarks).
|
||
|
||
#### segmentation_mask
|
||
|
||
The output segmentation mask, predicted only when
|
||
[enable_segmentation](#enable_segmentation) is set to `true`. The mask has the
|
||
same width and height as the input image, and contains values in `[0.0, 1.0]`
|
||
where `1.0` and `0.0` indicate high certainty of a "human" and "background"
|
||
pixel respectively. Please refer to the platform-specific usage examples below
|
||
for usage details.
|
||
|
||
### Python Solution API
|
||
|
||
Please first follow general [instructions](../getting_started/python.md) to
|
||
install MediaPipe Python package, then learn more in the companion
|
||
[Python Colab](#resources) and the usage example below.
|
||
|
||
Supported configuration options:
|
||
|
||
* [static_image_mode](#static_image_mode)
|
||
* [model_complexity](#model_complexity)
|
||
* [smooth_landmarks](#smooth_landmarks)
|
||
* [enable_segmentation](#enable_segmentation)
|
||
* [smooth_segmentation](#smooth_segmentation)
|
||
* [refine_face_landmarks](#refine_face_landmarks)
|
||
* [min_detection_confidence](#min_detection_confidence)
|
||
* [min_tracking_confidence](#min_tracking_confidence)
|
||
|
||
```python
|
||
import cv2
|
||
import mediapipe as mp
|
||
mp_drawing = mp.solutions.drawing_utils
|
||
mp_drawing_styles = mp.solutions.drawing_styles
|
||
mp_holistic = mp.solutions.holistic
|
||
|
||
# For static images:
|
||
IMAGE_FILES = []
|
||
BG_COLOR = (192, 192, 192) # gray
|
||
with mp_holistic.Holistic(
|
||
static_image_mode=True,
|
||
model_complexity=2,
|
||
enable_segmentation=True,
|
||
refine_face_landmarks=True) as holistic:
|
||
for idx, file in enumerate(IMAGE_FILES):
|
||
image = cv2.imread(file)
|
||
image_height, image_width, _ = image.shape
|
||
# Convert the BGR image to RGB before processing.
|
||
results = holistic.process(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
|
||
|
||
if results.pose_landmarks:
|
||
print(
|
||
f'Nose coordinates: ('
|
||
f'{results.pose_landmarks.landmark[mp_holistic.PoseLandmark.NOSE].x * image_width}, '
|
||
f'{results.pose_landmarks.landmark[mp_holistic.PoseLandmark.NOSE].y * image_height})'
|
||
)
|
||
|
||
annotated_image = image.copy()
|
||
# Draw segmentation on the image.
|
||
# To improve segmentation around boundaries, consider applying a joint
|
||
# bilateral filter to "results.segmentation_mask" with "image".
|
||
condition = np.stack((results.segmentation_mask,) * 3, axis=-1) > 0.1
|
||
bg_image = np.zeros(image.shape, dtype=np.uint8)
|
||
bg_image[:] = BG_COLOR
|
||
annotated_image = np.where(condition, annotated_image, bg_image)
|
||
# Draw pose, left and right hands, and face landmarks on the image.
|
||
mp_drawing.draw_landmarks(
|
||
annotated_image,
|
||
results.face_landmarks,
|
||
mp_holistic.FACEMESH_TESSELATION,
|
||
landmark_drawing_spec=None,
|
||
connection_drawing_spec=mp_drawing_styles
|
||
.get_default_face_mesh_tesselation_style())
|
||
mp_drawing.draw_landmarks(
|
||
annotated_image,
|
||
results.pose_landmarks,
|
||
mp_holistic.POSE_CONNECTIONS,
|
||
landmark_drawing_spec=mp_drawing_styles.
|
||
get_default_pose_landmarks_style())
|
||
cv2.imwrite('/tmp/annotated_image' + str(idx) + '.png', annotated_image)
|
||
# Plot pose world landmarks.
|
||
mp_drawing.plot_landmarks(
|
||
results.pose_world_landmarks, mp_holistic.POSE_CONNECTIONS)
|
||
|
||
# For webcam input:
|
||
cap = cv2.VideoCapture(0)
|
||
with mp_holistic.Holistic(
|
||
min_detection_confidence=0.5,
|
||
min_tracking_confidence=0.5) as holistic:
|
||
while cap.isOpened():
|
||
success, image = cap.read()
|
||
if not success:
|
||
print("Ignoring empty camera frame.")
|
||
# If loading a video, use 'break' instead of 'continue'.
|
||
continue
|
||
|
||
# To improve performance, optionally mark the image as not writeable to
|
||
# pass by reference.
|
||
image.flags.writeable = False
|
||
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
|
||
results = holistic.process(image)
|
||
|
||
# Draw landmark annotation on the image.
|
||
image.flags.writeable = True
|
||
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR)
|
||
mp_drawing.draw_landmarks(
|
||
image,
|
||
results.face_landmarks,
|
||
mp_holistic.FACEMESH_CONTOURS,
|
||
landmark_drawing_spec=None,
|
||
connection_drawing_spec=mp_drawing_styles
|
||
.get_default_face_mesh_contours_style())
|
||
mp_drawing.draw_landmarks(
|
||
image,
|
||
results.pose_landmarks,
|
||
mp_holistic.POSE_CONNECTIONS,
|
||
landmark_drawing_spec=mp_drawing_styles
|
||
.get_default_pose_landmarks_style())
|
||
# Flip the image horizontally for a selfie-view display.
|
||
cv2.imshow('MediaPipe Holistic', cv2.flip(image, 1))
|
||
if cv2.waitKey(5) & 0xFF == 27:
|
||
break
|
||
cap.release()
|
||
```
|
||
|
||
### JavaScript Solution API
|
||
|
||
Please first see general [introduction](../getting_started/javascript.md) on
|
||
MediaPipe in JavaScript, then learn more in the companion [web demo](#resources)
|
||
and the following usage example.
|
||
|
||
Supported configuration options:
|
||
|
||
* [modelComplexity](#model_complexity)
|
||
* [smoothLandmarks](#smooth_landmarks)
|
||
* [enableSegmentation](#enable_segmentation)
|
||
* [smoothSegmentation](#smooth_segmentation)
|
||
* [refineFaceLandmarks](#refineFaceLandmarks)
|
||
* [minDetectionConfidence](#min_detection_confidence)
|
||
* [minTrackingConfidence](#min_tracking_confidence)
|
||
|
||
```html
|
||
<!DOCTYPE html>
|
||
<html>
|
||
<head>
|
||
<meta charset="utf-8">
|
||
<script src="https://cdn.jsdelivr.net/npm/@mediapipe/camera_utils/camera_utils.js" crossorigin="anonymous"></script>
|
||
<script src="https://cdn.jsdelivr.net/npm/@mediapipe/control_utils/control_utils.js" crossorigin="anonymous"></script>
|
||
<script src="https://cdn.jsdelivr.net/npm/@mediapipe/drawing_utils/drawing_utils.js" crossorigin="anonymous"></script>
|
||
<script src="https://cdn.jsdelivr.net/npm/@mediapipe/holistic/holistic.js" crossorigin="anonymous"></script>
|
||
</head>
|
||
|
||
<body>
|
||
<div class="container">
|
||
<video class="input_video"></video>
|
||
<canvas class="output_canvas" width="1280px" height="720px"></canvas>
|
||
</div>
|
||
</body>
|
||
</html>
|
||
```
|
||
|
||
```javascript
|
||
<script type="module">
|
||
const videoElement = document.getElementsByClassName('input_video')[0];
|
||
const canvasElement = document.getElementsByClassName('output_canvas')[0];
|
||
const canvasCtx = canvasElement.getContext('2d');
|
||
|
||
function onResults(results) {
|
||
canvasCtx.save();
|
||
canvasCtx.clearRect(0, 0, canvasElement.width, canvasElement.height);
|
||
canvasCtx.drawImage(results.segmentationMask, 0, 0,
|
||
canvasElement.width, canvasElement.height);
|
||
|
||
// Only overwrite existing pixels.
|
||
canvasCtx.globalCompositeOperation = 'source-in';
|
||
canvasCtx.fillStyle = '#00FF00';
|
||
canvasCtx.fillRect(0, 0, canvasElement.width, canvasElement.height);
|
||
|
||
// Only overwrite missing pixels.
|
||
canvasCtx.globalCompositeOperation = 'destination-atop';
|
||
canvasCtx.drawImage(
|
||
results.image, 0, 0, canvasElement.width, canvasElement.height);
|
||
|
||
canvasCtx.globalCompositeOperation = 'source-over';
|
||
drawConnectors(canvasCtx, results.poseLandmarks, POSE_CONNECTIONS,
|
||
{color: '#00FF00', lineWidth: 4});
|
||
drawLandmarks(canvasCtx, results.poseLandmarks,
|
||
{color: '#FF0000', lineWidth: 2});
|
||
drawConnectors(canvasCtx, results.faceLandmarks, FACEMESH_TESSELATION,
|
||
{color: '#C0C0C070', lineWidth: 1});
|
||
drawConnectors(canvasCtx, results.leftHandLandmarks, HAND_CONNECTIONS,
|
||
{color: '#CC0000', lineWidth: 5});
|
||
drawLandmarks(canvasCtx, results.leftHandLandmarks,
|
||
{color: '#00FF00', lineWidth: 2});
|
||
drawConnectors(canvasCtx, results.rightHandLandmarks, HAND_CONNECTIONS,
|
||
{color: '#00CC00', lineWidth: 5});
|
||
drawLandmarks(canvasCtx, results.rightHandLandmarks,
|
||
{color: '#FF0000', lineWidth: 2});
|
||
canvasCtx.restore();
|
||
}
|
||
|
||
const holistic = new Holistic({locateFile: (file) => {
|
||
return `https://cdn.jsdelivr.net/npm/@mediapipe/holistic/${file}`;
|
||
}});
|
||
holistic.setOptions({
|
||
modelComplexity: 1,
|
||
smoothLandmarks: true,
|
||
enableSegmentation: true,
|
||
smoothSegmentation: true,
|
||
refineFaceLandmarks: true,
|
||
minDetectionConfidence: 0.5,
|
||
minTrackingConfidence: 0.5
|
||
});
|
||
holistic.onResults(onResults);
|
||
|
||
const camera = new Camera(videoElement, {
|
||
onFrame: async () => {
|
||
await holistic.send({image: videoElement});
|
||
},
|
||
width: 1280,
|
||
height: 720
|
||
});
|
||
camera.start();
|
||
</script>
|
||
```
|
||
|
||
## Example Apps
|
||
|
||
Please first see general instructions for
|
||
[Android](../getting_started/android.md), [iOS](../getting_started/ios.md), and
|
||
[desktop](../getting_started/cpp.md) on how to build MediaPipe examples.
|
||
|
||
Note: To visualize a graph, copy the graph and paste it into
|
||
[MediaPipe Visualizer](https://viz.mediapipe.dev/). For more information on how
|
||
to visualize its associated subgraphs, please see
|
||
[visualizer documentation](../tools/visualizer.md).
|
||
|
||
### Mobile
|
||
|
||
* Graph:
|
||
[`mediapipe/graphs/holistic_tracking/holistic_tracking_gpu.pbtxt`](https://github.com/google/mediapipe/tree/master/mediapipe/graphs/holistic_tracking/holistic_tracking_gpu.pbtxt)
|
||
* Android target:
|
||
[(or download prebuilt ARM64 APK)](https://drive.google.com/file/d/1o-Trp2GIRitA0OvmZWUQjVMa476xpfgK/view?usp=sharing)
|
||
[`mediapipe/examples/android/src/java/com/google/mediapipe/apps/holistictrackinggpu:holistictrackinggpu`](https://github.com/google/mediapipe/tree/master/mediapipe/examples/android/src/java/com/google/mediapipe/apps/holistictrackinggpu/BUILD)
|
||
* iOS target:
|
||
[`mediapipe/examples/ios/holistictrackinggpu:HolisticTrackingGpuApp`](http:/mediapipe/examples/ios/holistictrackinggpu/BUILD)
|
||
|
||
### Desktop
|
||
|
||
Please first see general instructions for [desktop](../getting_started/cpp.md)
|
||
on how to build MediaPipe examples.
|
||
|
||
* Running on CPU
|
||
* Graph:
|
||
[`mediapipe/graphs/holistic_tracking/holistic_tracking_cpu.pbtxt`](https://github.com/google/mediapipe/tree/master/mediapipe/graphs/holistic_tracking/holistic_tracking_cpu.pbtxt)
|
||
* Target:
|
||
[`mediapipe/examples/desktop/holistic_tracking:holistic_tracking_cpu`](https://github.com/google/mediapipe/tree/master/mediapipe/examples/desktop/holistic_tracking/BUILD)
|
||
* Running on GPU
|
||
* Graph:
|
||
[`mediapipe/graphs/holistic_tracking/holistic_tracking_gpu.pbtxt`](https://github.com/google/mediapipe/tree/master/mediapipe/graphs/holistic_tracking/holistic_tracking_gpu.pbtxt)
|
||
* Target:
|
||
[`mediapipe/examples/desktop/holistic_tracking:holistic_tracking_gpu`](https://github.com/google/mediapipe/tree/master/mediapipe/examples/desktop/holistic_tracking/BUILD)
|
||
|
||
## Resources
|
||
|
||
* Google AI Blog:
|
||
[MediaPipe Holistic - Simultaneous Face, Hand and Pose Prediction, on Device](https://ai.googleblog.com/2020/12/mediapipe-holistic-simultaneous-face.html)
|
||
* [Models and model cards](./models.md#holistic)
|
||
* [Web demo](https://code.mediapipe.dev/codepen/holistic)
|
||
* [Python Colab](https://mediapipe.page.link/holistic_py_colab)
|