---
layout: default
title: Face Mesh
parent: Solutions
nav_order: 2
---
# MediaPipe Face Mesh
{: .no_toc }
Table of contents
{: .text-delta }
1. TOC
{:toc}
---
## Overview
MediaPipe Face Mesh is a solution that estimates 468 3D face landmarks in
real-time even on mobile devices. It employs machine learning (ML) to infer the
3D facial surface, requiring only a single camera input without the need for a
dedicated depth sensor. Utilizing lightweight model architectures together with
GPU acceleration throughout the pipeline, the solution delivers real-time
performance critical for live experiences.
Additionally, the solution is bundled with the Face Transform module that
bridges the gap between the face landmark estimation and useful real-time
augmented reality (AR) applications. It establishes a metric 3D space and uses
the face landmark screen positions to estimate a face transform within that
space. The face transform data consists of common 3D primitives, including a
face pose transformation matrix and a triangular face mesh. Under the hood, a
lightweight statistical analysis method called
[Procrustes Analysis](https://en.wikipedia.org/wiki/Procrustes_analysis) is
employed to drive a robust, performant and portable logic. The analysis runs on
CPU and has a minimal speed/memory footprint on top of the ML model inference.
 |
:-------------------------------------------------------------: |
*Fig 1. AR effects utilizing the 3D facial surface.* |
## ML Pipeline
Our ML pipeline consists of two real-time deep neural network models that work
together: A detector that operates on the full image and computes face locations
and a 3D face landmark model that operates on those locations and predicts the
approximate 3D surface via regression. Having the face accurately cropped
drastically reduces the need for common data augmentations like affine
transformations consisting of rotations, translation and scale changes. Instead
it allows the network to dedicate most of its capacity towards coordinate
prediction accuracy. In addition, in our pipeline the crops can also be
generated based on the face landmarks identified in the previous frame, and only
when the landmark model could no longer identify face presence is the face
detector invoked to relocalize the face. This strategy is similar to that
employed in our [MediaPipe Hands](./hands.md) solution, which uses a palm
detector together with a hand landmark model.
The pipeline is implemented as a MediaPipe
[graph](https://github.com/google/mediapipe/tree/master/mediapipe/graphs/face_mesh/face_mesh_mobile.pbtxt)
that uses a
[face landmark subgraph](https://github.com/google/mediapipe/tree/master/mediapipe/modules/face_landmark/face_landmark_front_gpu.pbtxt)
from the
[face landmark module](https://github.com/google/mediapipe/tree/master/mediapipe/modules/face_landmark),
and renders using a dedicated
[face renderer subgraph](https://github.com/google/mediapipe/tree/master/mediapipe/graphs/face_mesh/subgraphs/face_renderer_gpu.pbtxt).
The
[face landmark subgraph](https://github.com/google/mediapipe/tree/master/mediapipe/modules/face_landmark/face_landmark_front_gpu.pbtxt)
internally uses a
[face_detection_subgraph](https://github.com/google/mediapipe/tree/master/mediapipe/modules/face_detection/face_detection_short_range_gpu.pbtxt)
from the
[face detection module](https://github.com/google/mediapipe/tree/master/mediapipe/modules/face_detection).
Note: To visualize a graph, copy the graph and paste it into
[MediaPipe Visualizer](https://viz.mediapipe.dev/). For more information on how
to visualize its associated subgraphs, please see
[visualizer documentation](../tools/visualizer.md).
### Models
#### Face Detection Model
The face detector is the same [BlazeFace](https://arxiv.org/abs/1907.05047)
model used in [MediaPipe Face Detection](./face_detection.md). Please refer to
[MediaPipe Face Detection](./face_detection.md) for details.
#### Face Landmark Model
For 3D face landmarks we employed transfer learning and trained a network with
several objectives: the network simultaneously predicts 3D landmark coordinates
on synthetic rendered data and 2D semantic contours on annotated real-world
data. The resulting network provided us with reasonable 3D landmark predictions
not just on synthetic but also on real-world data.
The 3D landmark network receives as input a cropped video frame without
additional depth input. The model outputs the positions of the 3D points, as
well as the probability of a face being present and reasonably aligned in the
input. A common alternative approach is to predict a 2D heatmap for each
landmark, but it is not amenable to depth prediction and has high computational
costs for so many points. We further improve the accuracy and robustness of our
model by iteratively bootstrapping and refining predictions. That way we can
grow our dataset to increasingly challenging cases, such as grimaces, oblique
angle and occlusions.
You can find more information about the face landmark model in this
[paper](https://arxiv.org/abs/1907.06724).
 |
:------------------------------------------------------------------------: |
*Fig 2. Face landmarks: the red box indicates the cropped area as input to the landmark model, the red dots represent the 468 landmarks in 3D, and the green lines connecting landmarks illustrate the contours around the eyes, eyebrows, lips and the entire face.* |
#### Attention Mesh Model
In addition to the [Face Landmark Model](#face-landmark-model) we provide
another model that applies
[attention](https://en.wikipedia.org/wiki/Attention_(machine_learning)) to
semantically meaningful face regions, and therefore predicting landmarks more
accurately around lips, eyes and irises, at the expense of more compute. It
enables applications like AR makeup and AR puppeteering.
The attention mesh model can be selected in the Solution APIs via the
[refine_landmarks](#refine_landmarks) option. You can also find more information
about the model in this [paper](https://arxiv.org/abs/2006.10962).
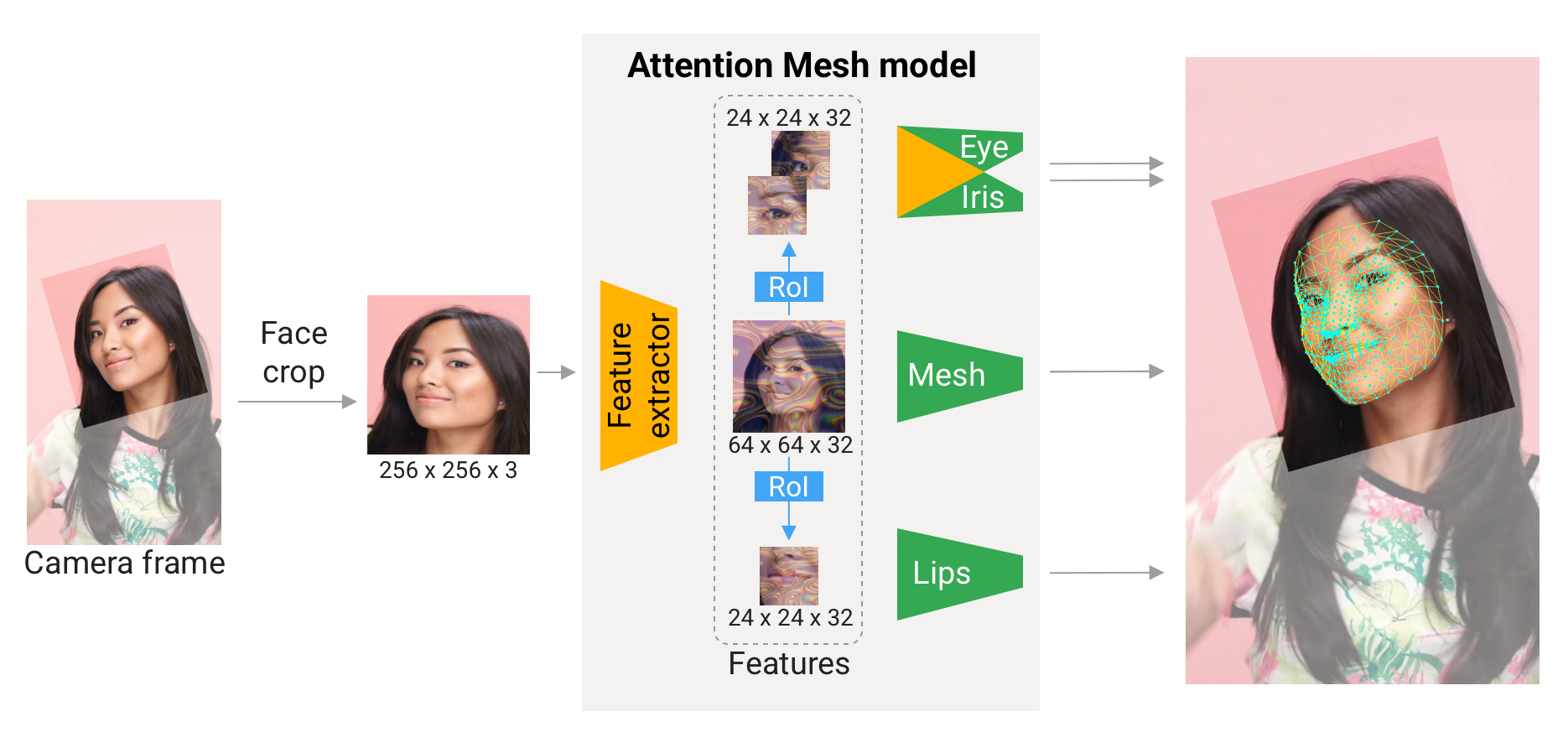 |
:---------------------------------------------------------------------------: |
*Fig 3. Attention Mesh: Overview of model architecture.* |
## Face Transform Module
The [Face Landmark Model](#face-landmark-model) performs a single-camera face landmark
detection in the screen coordinate space: the X- and Y- coordinates are
normalized screen coordinates, while the Z coordinate is relative and is scaled
as the X coodinate under the
[weak perspective projection camera model](https://en.wikipedia.org/wiki/3D_projection#Weak_perspective_projection).
This format is well-suited for some applications, however it does not directly
enable the full spectrum of augmented reality (AR) features like aligning a
virtual 3D object with a detected face.
The
[Face Transform module](https://github.com/google/mediapipe/tree/master/mediapipe/modules/face_geometry)
moves away from the screen coordinate space towards a metric 3D space and
provides necessary primitives to handle a detected face as a regular 3D object.
By design, you'll be able to use a perspective camera to project the final 3D
scene back into the screen coordinate space with a guarantee that the face
landmark positions are not changed.
### Key Concepts
#### Metric 3D Space
The **Metric 3D space** established within the Face Transform module is a
right-handed orthonormal metric 3D coordinate space. Within the space, there is
a **virtual perspective camera** located at the space origin and pointed in the
negative direction of the Z-axis. In the current pipeline, it is assumed that
the input camera frames are observed by exactly this virtual camera and
therefore its parameters are later used to convert the screen landmark
coordinates back into the Metric 3D space. The *virtual camera parameters* can
be set freely, however for better results it is advised to set them as close to
the *real physical camera parameters* as possible.
 |
:-------------------------------------------------------------------------------: |
*Fig 4. A visualization of multiple key elements in the Metric 3D space.* |
#### Canonical Face Model
The **Canonical Face Model** is a static 3D model of a human face, which follows
the 468 3D face landmark topology of the
[Face Landmark Model](#face-landmark-model). The model bears two important
functions:
- **Defines metric units**: the scale of the canonical face model defines the
metric units of the Metric 3D space. A metric unit used by the
[default canonical face model](https://github.com/google/mediapipe/tree/master/mediapipe/modules/face_geometry/data/canonical_face_model.fbx)
is a centimeter;
- **Bridges static and runtime spaces**: the face pose transformation matrix
is - in fact - a linear map from the canonical face model into the runtime
face landmark set estimated on each frame. This way, virtual 3D assets
modeled around the canonical face model can be aligned with a tracked face
by applying the face pose transformation matrix to them.
### Components
#### Transform Pipeline
The **Transform Pipeline** is a key component, which is responsible for
estimating the face transform objects within the Metric 3D space. On each frame,
the following steps are executed in the given order:
- Face landmark screen coordinates are converted into the Metric 3D space
coordinates;
- Face pose transformation matrix is estimated as a rigid linear mapping from
the canonical face metric landmark set into the runtime face metric landmark
set in a way that minimizes a difference between the two;
- A face mesh is created using the runtime face metric landmarks as the vertex
positions (XYZ), while both the vertex texture coordinates (UV) and the
triangular topology are inherited from the canonical face model.
The transform pipeline is implemented as a MediaPipe
[calculator](https://github.com/google/mediapipe/tree/master/mediapipe/modules/face_geometry/geometry_pipeline_calculator.cc).
For your convenience, this calculator is bundled together with corresponding
metadata into a unified MediaPipe
[subgraph](https://github.com/google/mediapipe/tree/master/mediapipe/modules/face_geometry/face_geometry_from_landmarks.pbtxt).
The face transform format is defined as a Protocol Buffer
[message](https://github.com/google/mediapipe/tree/master/mediapipe/modules/face_geometry/protos/face_geometry.proto).
#### Effect Renderer
The **Effect Renderer** is a component, which serves as a working example of a
face effect renderer. It targets the *OpenGL ES 2.0* API to enable a real-time
performance on mobile devices and supports the following rendering modes:
- **3D object rendering mode**: a virtual object is aligned with a detected
face to emulate an object attached to the face (example: glasses);
- **Face mesh rendering mode**: a texture is stretched on top of the face mesh
surface to emulate a face painting technique.
In both rendering modes, the face mesh is first rendered as an occluder straight
into the depth buffer. This step helps to create a more believable effect via
hiding invisible elements behind the face surface.
The effect renderer is implemented as a MediaPipe
[calculator](https://github.com/google/mediapipe/tree/master/mediapipe/modules/face_geometry/effect_renderer_calculator.cc).
|  |
| :---------------------------------------------------------------------: |
| *Fig 5. An example of face effects rendered by the Face Transform Effect Renderer.* |
## Solution APIs
### Configuration Options
Naming style and availability may differ slightly across platforms/languages.
#### static_image_mode
If set to `false`, the solution treats the input images as a video stream. It
will try to detect faces in the first input images, and upon a successful
detection further localizes the face landmarks. In subsequent images, once all
[max_num_faces](#max_num_faces) faces are detected and the corresponding face
landmarks are localized, it simply tracks those landmarks without invoking
another detection until it loses track of any of the faces. This reduces latency
and is ideal for processing video frames. If set to `true`, face detection runs
on every input image, ideal for processing a batch of static, possibly
unrelated, images. Default to `false`.
#### max_num_faces
Maximum number of faces to detect. Default to `1`.
#### refine_landmarks
Whether to further refine the landmark coordinates around the eyes and lips, and
output additional landmarks around the irises by applying the
[Attention Mesh Model](#attention-mesh-model). Default to `false`.
#### min_detection_confidence
Minimum confidence value (`[0.0, 1.0]`) from the face detection model for the
detection to be considered successful. Default to `0.5`.
#### min_tracking_confidence
Minimum confidence value (`[0.0, 1.0]`) from the landmark-tracking model for the
face landmarks to be considered tracked successfully, or otherwise face
detection will be invoked automatically on the next input image. Setting it to a
higher value can increase robustness of the solution, at the expense of a higher
latency. Ignored if [static_image_mode](#static_image_mode) is `true`, where
face detection simply runs on every image. Default to `0.5`.
### Output
Naming style may differ slightly across platforms/languages.
#### multi_face_landmarks
Collection of detected/tracked faces, where each face is represented as a list
of 468 face landmarks and each landmark is composed of `x`, `y` and `z`. `x` and
`y` are normalized to `[0.0, 1.0]` by the image width and height respectively.
`z` represents the landmark depth with the depth at center of the head being the
origin, and the smaller the value the closer the landmark is to the camera. The
magnitude of `z` uses roughly the same scale as `x`.
### Python Solution API
Please first follow general [instructions](../getting_started/python.md) to
install MediaPipe Python package, then learn more in the companion
[Python Colab](#resources) and the usage example below.
Supported configuration options:
* [static_image_mode](#static_image_mode)
* [max_num_faces](#max_num_faces)
* [refine_landmarks](#refine_landmarks)
* [min_detection_confidence](#min_detection_confidence)
* [min_tracking_confidence](#min_tracking_confidence)
```python
import cv2
import mediapipe as mp
mp_drawing = mp.solutions.drawing_utils
mp_drawing_styles = mp.solutions.drawing_styles
mp_face_mesh = mp.solutions.face_mesh
# For static images:
IMAGE_FILES = []
drawing_spec = mp_drawing.DrawingSpec(thickness=1, circle_radius=1)
with mp_face_mesh.FaceMesh(
static_image_mode=True,
max_num_faces=1,
refine_landmarks=True,
min_detection_confidence=0.5) as face_mesh:
for idx, file in enumerate(IMAGE_FILES):
image = cv2.imread(file)
# Convert the BGR image to RGB before processing.
results = face_mesh.process(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
# Print and draw face mesh landmarks on the image.
if not results.multi_face_landmarks:
continue
annotated_image = image.copy()
for face_landmarks in results.multi_face_landmarks:
print('face_landmarks:', face_landmarks)
mp_drawing.draw_landmarks(
image=annotated_image,
landmark_list=face_landmarks,
connections=mp_face_mesh.FACEMESH_TESSELATION,
landmark_drawing_spec=None,
connection_drawing_spec=mp_drawing_styles
.get_default_face_mesh_tesselation_style())
mp_drawing.draw_landmarks(
image=annotated_image,
landmark_list=face_landmarks,
connections=mp_face_mesh.FACEMESH_CONTOURS,
landmark_drawing_spec=None,
connection_drawing_spec=mp_drawing_styles
.get_default_face_mesh_contours_style())
mp_drawing.draw_landmarks(
image=annotated_image,
landmark_list=face_landmarks,
connections=mp_face_mesh.FACEMESH_IRISES,
landmark_drawing_spec=None,
connection_drawing_spec=mp_drawing_styles
.get_default_face_mesh_iris_connections_style())
cv2.imwrite('/tmp/annotated_image' + str(idx) + '.png', annotated_image)
# For webcam input:
drawing_spec = mp_drawing.DrawingSpec(thickness=1, circle_radius=1)
cap = cv2.VideoCapture(0)
with mp_face_mesh.FaceMesh(
max_num_faces=1,
refine_landmarks=True,
min_detection_confidence=0.5,
min_tracking_confidence=0.5) as face_mesh:
while cap.isOpened():
success, image = cap.read()
if not success:
print("Ignoring empty camera frame.")
# If loading a video, use 'break' instead of 'continue'.
continue
# To improve performance, optionally mark the image as not writeable to
# pass by reference.
image.flags.writeable = False
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
results = face_mesh.process(image)
# Draw the face mesh annotations on the image.
image.flags.writeable = True
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR)
if results.multi_face_landmarks:
for face_landmarks in results.multi_face_landmarks:
mp_drawing.draw_landmarks(
image=image,
landmark_list=face_landmarks,
connections=mp_face_mesh.FACEMESH_TESSELATION,
landmark_drawing_spec=None,
connection_drawing_spec=mp_drawing_styles
.get_default_face_mesh_tesselation_style())
mp_drawing.draw_landmarks(
image=image,
landmark_list=face_landmarks,
connections=mp_face_mesh.FACEMESH_CONTOURS,
landmark_drawing_spec=None,
connection_drawing_spec=mp_drawing_styles
.get_default_face_mesh_contours_style())
mp_drawing.draw_landmarks(
image=image,
landmark_list=face_landmarks,
connections=mp_face_mesh.FACEMESH_IRISES,
landmark_drawing_spec=None,
connection_drawing_spec=mp_drawing_styles
.get_default_face_mesh_iris_connections_style())
# Flip the image horizontally for a selfie-view display.
cv2.imshow('MediaPipe Face Mesh', cv2.flip(image, 1))
if cv2.waitKey(5) & 0xFF == 27:
break
cap.release()
```
### JavaScript Solution API
Please first see general [introduction](../getting_started/javascript.md) on
MediaPipe in JavaScript, then learn more in the companion [web demo](#resources)
and the following usage example.
Supported configuration options:
* [maxNumFaces](#max_num_faces)
* [refineLandmarks](#refine_landmarks)
* [minDetectionConfidence](#min_detection_confidence)
* [minTrackingConfidence](#min_tracking_confidence)
```html
```
```javascript
```
### Android Solution API
Please first follow general
[instructions](../getting_started/android_solutions.md) to add MediaPipe Gradle
dependencies and try the Android Solution API in the companion
[example Android Studio project](https://github.com/google/mediapipe/tree/master/mediapipe/examples/android/solutions/facemesh),
and learn more in the usage example below.
Supported configuration options:
* [staticImageMode](#static_image_mode)
* [maxNumFaces](#max_num_faces)
* [refineLandmarks](#refine_landmarks)
* runOnGpu: Run the pipeline and the model inference on GPU or CPU.
#### Camera Input
```java
// For camera input and result rendering with OpenGL.
FaceMeshOptions faceMeshOptions =
FaceMeshOptions.builder()
.setStaticImageMode(false)
.setRefineLandmarks(true)
.setMaxNumFaces(1)
.setRunOnGpu(true).build();
FaceMesh faceMesh = new FaceMesh(this, faceMeshOptions);
faceMesh.setErrorListener(
(message, e) -> Log.e(TAG, "MediaPipe Face Mesh error:" + message));
// Initializes a new CameraInput instance and connects it to MediaPipe Face Mesh Solution.
CameraInput cameraInput = new CameraInput(this);
cameraInput.setNewFrameListener(
textureFrame -> faceMesh.send(textureFrame));
// Initializes a new GlSurfaceView with a ResultGlRenderer instance
// that provides the interfaces to run user-defined OpenGL rendering code.
// See mediapipe/examples/android/solutions/facemesh/src/main/java/com/google/mediapipe/examples/facemesh/FaceMeshResultGlRenderer.java
// as an example.
SolutionGlSurfaceView glSurfaceView =
new SolutionGlSurfaceView<>(
this, faceMesh.getGlContext(), faceMesh.getGlMajorVersion());
glSurfaceView.setSolutionResultRenderer(new FaceMeshResultGlRenderer());
glSurfaceView.setRenderInputImage(true);
faceMesh.setResultListener(
faceMeshResult -> {
NormalizedLandmark noseLandmark =
result.multiFaceLandmarks().get(0).getLandmarkList().get(1);
Log.i(
TAG,
String.format(
"MediaPipe Face Mesh nose normalized coordinates (value range: [0, 1]): x=%f, y=%f",
noseLandmark.getX(), noseLandmark.getY()));
// Request GL rendering.
glSurfaceView.setRenderData(faceMeshResult);
glSurfaceView.requestRender();
});
// The runnable to start camera after the GLSurfaceView is attached.
glSurfaceView.post(
() ->
cameraInput.start(
this,
faceMesh.getGlContext(),
CameraInput.CameraFacing.FRONT,
glSurfaceView.getWidth(),
glSurfaceView.getHeight()));
```
#### Image Input
```java
// For reading images from gallery and drawing the output in an ImageView.
FaceMeshOptions faceMeshOptions =
FaceMeshOptions.builder()
.setStaticImageMode(true)
.setRefineLandmarks(true)
.setMaxNumFaces(1)
.setRunOnGpu(true).build();
FaceMesh faceMesh = new FaceMesh(this, faceMeshOptions);
// Connects MediaPipe Face Mesh Solution to the user-defined ImageView instance
// that allows users to have the custom drawing of the output landmarks on it.
// See mediapipe/examples/android/solutions/facemesh/src/main/java/com/google/mediapipe/examples/facemesh/FaceMeshResultImageView.java
// as an example.
FaceMeshResultImageView imageView = new FaceMeshResultImageView(this);
faceMesh.setResultListener(
faceMeshResult -> {
int width = faceMeshResult.inputBitmap().getWidth();
int height = faceMeshResult.inputBitmap().getHeight();
NormalizedLandmark noseLandmark =
result.multiFaceLandmarks().get(0).getLandmarkList().get(1);
Log.i(
TAG,
String.format(
"MediaPipe Face Mesh nose coordinates (pixel values): x=%f, y=%f",
noseLandmark.getX() * width, noseLandmark.getY() * height));
// Request canvas drawing.
imageView.setFaceMeshResult(faceMeshResult);
runOnUiThread(() -> imageView.update());
});
faceMesh.setErrorListener(
(message, e) -> Log.e(TAG, "MediaPipe Face Mesh error:" + message));
// ActivityResultLauncher to get an image from the gallery as Bitmap.
ActivityResultLauncher imageGetter =
registerForActivityResult(
new ActivityResultContracts.StartActivityForResult(),
result -> {
Intent resultIntent = result.getData();
if (resultIntent != null && result.getResultCode() == RESULT_OK) {
Bitmap bitmap = null;
try {
bitmap =
MediaStore.Images.Media.getBitmap(
this.getContentResolver(), resultIntent.getData());
// Please also rotate the Bitmap based on its orientation.
} catch (IOException e) {
Log.e(TAG, "Bitmap reading error:" + e);
}
if (bitmap != null) {
faceMesh.send(bitmap);
}
}
});
Intent pickImageIntent = new Intent(Intent.ACTION_PICK);
pickImageIntent.setDataAndType(MediaStore.Images.Media.INTERNAL_CONTENT_URI, "image/*");
imageGetter.launch(pickImageIntent);
```
#### Video Input
```java
// For video input and result rendering with OpenGL.
FaceMeshOptions faceMeshOptions =
FaceMeshOptions.builder()
.setStaticImageMode(false)
.setRefineLandmarks(true)
.setMaxNumFaces(1)
.setRunOnGpu(true).build();
FaceMesh faceMesh = new FaceMesh(this, faceMeshOptions);
faceMesh.setErrorListener(
(message, e) -> Log.e(TAG, "MediaPipe Face Mesh error:" + message));
// Initializes a new VideoInput instance and connects it to MediaPipe Face Mesh Solution.
VideoInput videoInput = new VideoInput(this);
videoInput.setNewFrameListener(
textureFrame -> faceMesh.send(textureFrame));
// Initializes a new GlSurfaceView with a ResultGlRenderer instance
// that provides the interfaces to run user-defined OpenGL rendering code.
// See mediapipe/examples/android/solutions/facemesh/src/main/java/com/google/mediapipe/examples/facemesh/FaceMeshResultGlRenderer.java
// as an example.
SolutionGlSurfaceView glSurfaceView =
new SolutionGlSurfaceView<>(
this, faceMesh.getGlContext(), faceMesh.getGlMajorVersion());
glSurfaceView.setSolutionResultRenderer(new FaceMeshResultGlRenderer());
glSurfaceView.setRenderInputImage(true);
faceMesh.setResultListener(
faceMeshResult -> {
NormalizedLandmark noseLandmark =
result.multiFaceLandmarks().get(0).getLandmarkList().get(1);
Log.i(
TAG,
String.format(
"MediaPipe Face Mesh nose normalized coordinates (value range: [0, 1]): x=%f, y=%f",
noseLandmark.getX(), noseLandmark.getY()));
// Request GL rendering.
glSurfaceView.setRenderData(faceMeshResult);
glSurfaceView.requestRender();
});
ActivityResultLauncher videoGetter =
registerForActivityResult(
new ActivityResultContracts.StartActivityForResult(),
result -> {
Intent resultIntent = result.getData();
if (resultIntent != null) {
if (result.getResultCode() == RESULT_OK) {
glSurfaceView.post(
() ->
videoInput.start(
this,
resultIntent.getData(),
faceMesh.getGlContext(),
glSurfaceView.getWidth(),
glSurfaceView.getHeight()));
}
}
});
Intent pickVideoIntent = new Intent(Intent.ACTION_PICK);
pickVideoIntent.setDataAndType(MediaStore.Video.Media.INTERNAL_CONTENT_URI, "video/*");
videoGetter.launch(pickVideoIntent);
```
## Example Apps
Please first see general instructions for
[Android](../getting_started/android.md), [iOS](../getting_started/ios.md) and
[desktop](../getting_started/cpp.md) on how to build MediaPipe examples.
Note: To visualize a graph, copy the graph and paste it into
[MediaPipe Visualizer](https://viz.mediapipe.dev/). For more information on how
to visualize its associated subgraphs, please see
[visualizer documentation](../tools/visualizer.md).
### Face Landmark Example
Face landmark example showcases real-time, cross-platform face landmark
detection. For visual reference, please refer to *Fig. 2*.
#### Mobile
* Graph:
[`mediapipe/graphs/face_mesh/face_mesh_mobile.pbtxt`](https://github.com/google/mediapipe/tree/master/mediapipe/graphs/face_mesh/face_mesh_mobile.pbtxt)
* Android target:
[(or download prebuilt ARM64 APK)](https://drive.google.com/open?id=1pUmd7CXCL_onYMbsZo5p91cH0oNnR4gi)
[`mediapipe/examples/android/src/java/com/google/mediapipe/apps/facemeshgpu:facemeshgpu`](https://github.com/google/mediapipe/tree/master/mediapipe/examples/android/src/java/com/google/mediapipe/apps/facemeshgpu/BUILD)
* iOS target:
[`mediapipe/examples/ios/facemeshgpu:FaceMeshGpuApp`](http:/mediapipe/examples/ios/facemeshgpu/BUILD)
Tip: Maximum number of faces to detect/process is set to 1 by default. To change
it, for Android modify `NUM_FACES` in
[MainActivity.java](https://github.com/google/mediapipe/tree/master/mediapipe/examples/android/src/java/com/google/mediapipe/apps/facemeshgpu/MainActivity.java),
and for iOS modify `kNumFaces` in
[FaceMeshGpuViewController.mm](https://github.com/google/mediapipe/tree/master/mediapipe/examples/ios/facemeshgpu/FaceMeshGpuViewController.mm).
#### Desktop
* Running on CPU
* Graph:
[`mediapipe/graphs/face_mesh/face_mesh_desktop_live.pbtxt`](https://github.com/google/mediapipe/tree/master/mediapipe/graphs/face_mesh/face_mesh_desktop_live.pbtxt)
* Target:
[`mediapipe/examples/desktop/face_mesh:face_mesh_cpu`](https://github.com/google/mediapipe/tree/master/mediapipe/examples/desktop/face_mesh/BUILD)
* Running on GPU
* Graph:
[`mediapipe/graphs/face_mesh/face_mesh_desktop_live_gpu.pbtxt`](https://github.com/google/mediapipe/tree/master/mediapipe/graphs/face_mesh/face_mesh_desktop_live_gpu.pbtxt)
* Target:
[`mediapipe/examples/desktop/face_mesh:face_mesh_gpu`](https://github.com/google/mediapipe/tree/master/mediapipe/examples/desktop/face_mesh/BUILD)
Tip: Maximum number of faces to detect/process is set to 1 by default. To change
it, in the graph file modify the option of `ConstantSidePacketCalculator`.
### Face Effect Example
Face effect example showcases real-time mobile face effect application use case
for the Face Mesh solution. To enable a better user experience, this example
only works for a single face. For visual reference, please refer to *Fig. 4*.
#### Mobile
* Graph:
[`mediapipe/graphs/face_effect/face_effect_gpu.pbtxt`](https://github.com/google/mediapipe/tree/master/mediapipe/graphs/face_effect/face_effect_gpu.pbtxt)
* Android target:
[(or download prebuilt ARM64 APK)](https://drive.google.com/file/d/1ccnaDnffEuIXriBZr2SK_Eu4FpO7K44s)
[`mediapipe/examples/android/src/java/com/google/mediapipe/apps/faceeffect`](https://github.com/google/mediapipe/tree/master/mediapipe/examples/android/src/java/com/google/mediapipe/apps/faceeffect/BUILD)
* iOS target:
[`mediapipe/examples/ios/faceeffect`](http:/mediapipe/examples/ios/faceeffect/BUILD)
## Resources
* Google AI Blog:
[Real-Time AR Self-Expression with Machine Learning](https://ai.googleblog.com/2019/03/real-time-ar-self-expression-with.html)
* TensorFlow Blog:
[Face and hand tracking in the browser with MediaPipe and TensorFlow.js](https://blog.tensorflow.org/2020/03/face-and-hand-tracking-in-browser-with-mediapipe-and-tensorflowjs.html)
* Google Developers Blog:
[MediaPipe 3D Face Transform](https://developers.googleblog.com/2020/09/mediapipe-3d-face-transform.html)
* Paper:
[Real-time Facial Surface Geometry from Monocular Video on Mobile GPUs](https://arxiv.org/abs/1907.06724)
([poster](https://docs.google.com/presentation/d/1-LWwOMO9TzEVdrZ1CS1ndJzciRHfYDJfbSxH_ke_JRg/present?slide=id.g5986dd4b4c_4_212))
* Canonical face model:
[FBX](https://github.com/google/mediapipe/tree/master/mediapipe/modules/face_geometry/data/canonical_face_model.fbx),
[OBJ](https://github.com/google/mediapipe/tree/master/mediapipe/modules/face_geometry/data/canonical_face_model.obj),
[UV visualization](https://github.com/google/mediapipe/tree/master/mediapipe/modules/face_geometry/data/canonical_face_model_uv_visualization.png)
* [Models and model cards](./models.md#face_mesh)
* [Web demo](https://code.mediapipe.dev/codepen/face_mesh)
* [Python Colab](https://mediapipe.page.link/face_mesh_py_colab)